

Hrátky s Code Interpretrem, tedy novou funkcí chatGPT, jsou celkem zábava, byť mám zatím pochyby o slibované ohromující efektivitě, jak někteří tvrdí. Podívejte se například zde na ty „mind-blowing” příklady:
🚨 BREAKING: Code Interpreter is FINALLY rolling out to all ChatGPT Plus users.
— Aakash Gupta 🚀 Product Growth Guy (@aakashg0) July 7, 2023
It's the most powerful feature OpenAI has released since GPT-4. It makes everyone a data analyst.
Here are 15 mind-blowing use cases of Code Interpreter: pic.twitter.com/qX0txynENS
nebo tady:
The biggest compilation of what ChatGPT Code Interpreter can do
— Chase Lean (@chaseleantj) July 8, 2023
Code Interpreter is hands down the most powerful version of ChatGPT.
I spent 3 hours compiling the best Tweets on this feature.
Below are 20 amazing examples of how people are using it right now: pic.twitter.com/TJ7mOqrGXz
Mám smíšenou zkušenost. Nadějné, ale zatím ne jednoduše použitelné a spolehlivé.
Nejdřív: jak Code Interpreter aktivovat a používat?
- Podmínka: musíte mít placenou chatGPT Plus
- v Settings najdete Beta features a zapnete Code Interpreter
- zvolíte chat v režimu Code Interpreter Beta
Jedním z největších přínosů Code Interpretru (CI) je, že můžete nahrát vlastní soubor s daty a nechat jej zpracovat. Může jít o tabulku, obrázek, PDF či GIF apod. Code Interpreter pak vytvoří vlastní skript, kterým data zpracuje dle vašeho zadání – například vizualizuje do grafu. (a taky z fotky či GIFu udělá video, ale na to už je milion lepších nástrojů).
Učinil jsem několik pokusů zadat CI různé úkoly – žádný nešel tak hladce a ohromujícně, jak v cherry-picknutých vláknech z twitteru výše. Možná je to ale češtinou při formulaci zadání, nebo i češtinou v podkladech, které jsem modelu nabízel. Český jazykový model uvnitř chatGPT bude asi hloupější nejen při porozumění a generování textu, ale následně i při vytváření vnitřního zadání pro CI. (toto nemám ověřené, jen spekuluji).
Následují mé dva pokusy (za mě typické průběhem i výsledkem).
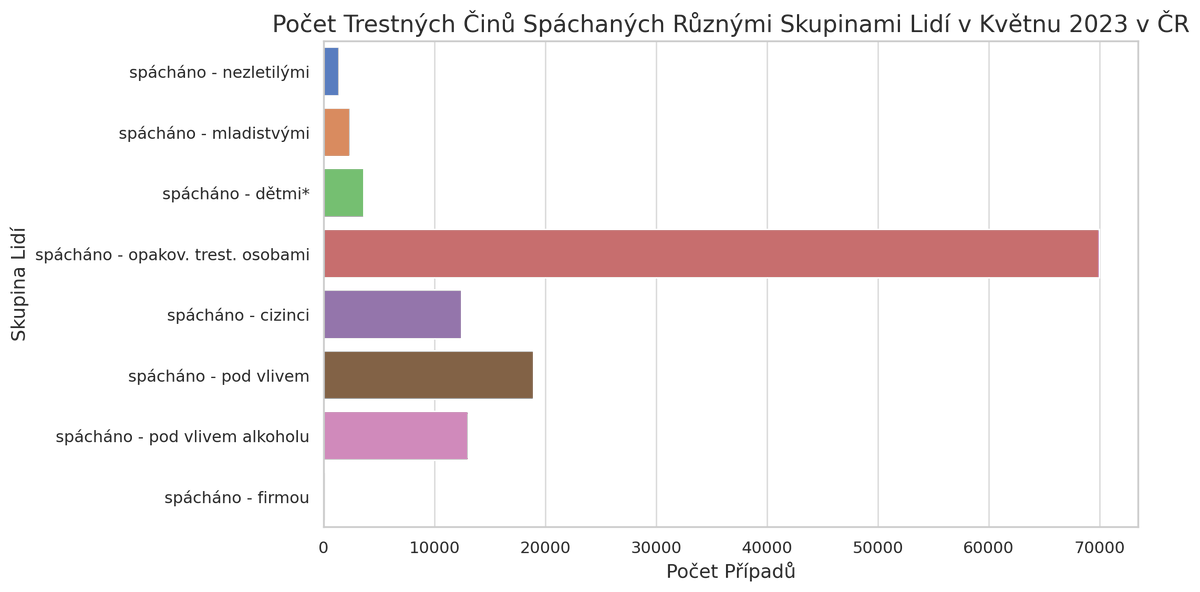
Pokus číslo 1: najdi nejzajímavější data ze statistiky kriminality za měsíc květen 2023 v ČR a vizualizuj je
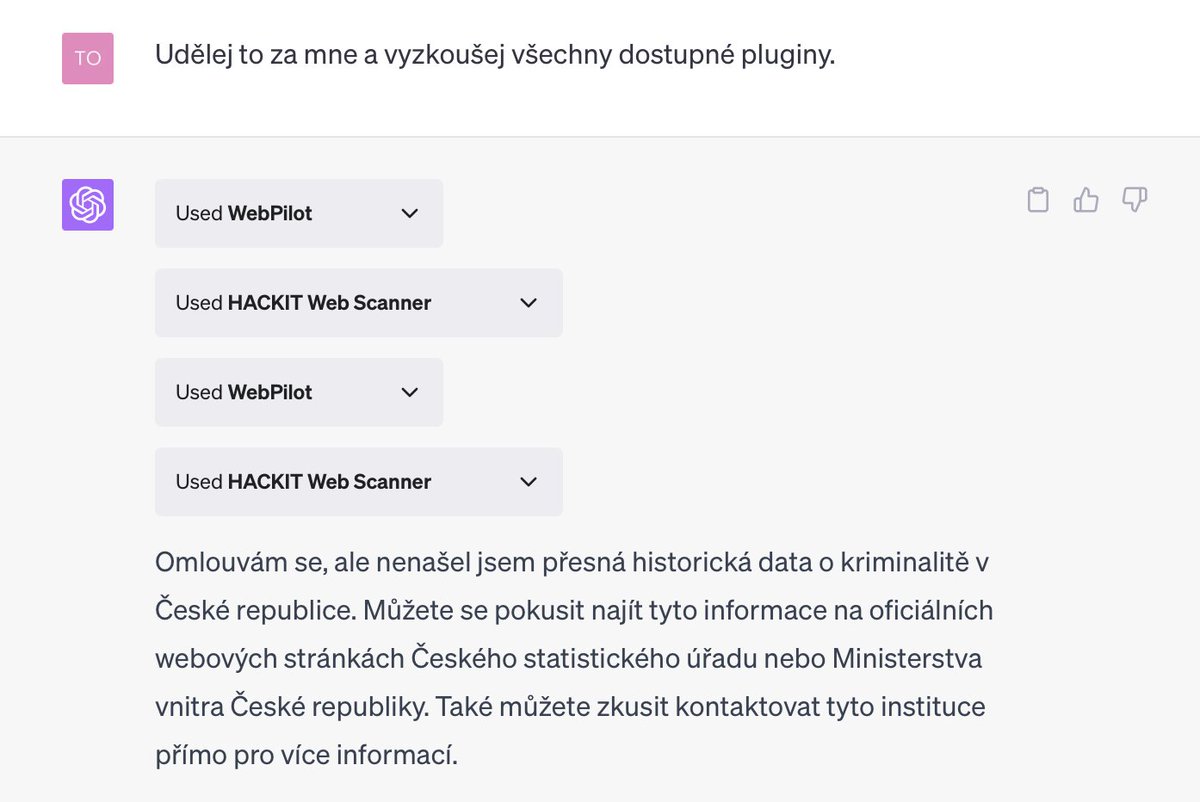
CI zatím nemá přístup na internet: data si musíte připravit sami a soubor nahrát. Pokud jste používali chatGPT s Bingem (s vyhledáváním na internetu – nyní dočasně pozastaveno), anebo využíváte pluginy WebPilot či HACKIT WebScanner (dělají totéž a opět je lze aktivovat jen v placené verzi chatGPT), nefungují přímo v chatu Code Interpreteru. V jednom chatu (či pomocí googlu :) tedy případně rešeršujete zdrojová data, v druhém je pak zvlášť nahráváte k analýze.
Mé pokusy o automatickou rešerši dat o kriminalitě v ČR s využitím web pluginů však i tak skončily fiaskem. Selhal i plugin Wolfram. Přitom data na webu ČSÚ jsou, takže jsem je musel stáhnout sám odtud: https://www.policie.cz/clanek/statisticke-prehledy-kriminality-za-rok-2023.aspx. Vyřešil to Google, tedy spíše bezpečnější DuckDuckGo, které místo něj běžně používám.
Data jsem pak konečně nahrál v chatu CI s patřičným promptem a požádal o analýzu. Samomluva i následná diskuse byla zpočátku velice nadějná, protože CI velmi dobře rozebral, „pochopil” a vyčistil tabulku. Vykreslil také jednoduché grafy (jeden z nich je výše, ostatní jsem ztratil, jak vysvětluju pro změnu níže).

Pak se ale to ale začalo zvrtávat, to když jsem požádal CI o nalezení „zajímavých korelací”. Ukázal mi matici, v níž koreloval např. počet trestných činů s objasněností či způsobenou škodou – vztahy, které jsou spíše zjevné. Poprosil jsem tedy o něco ještě zajímavějšího a méně zjevného. Tehdy se však zacyklil a už se neprobral. Opakovaně zobrazoval korelaci proměnné se sebou samou, a nedal si to rozmluvit:
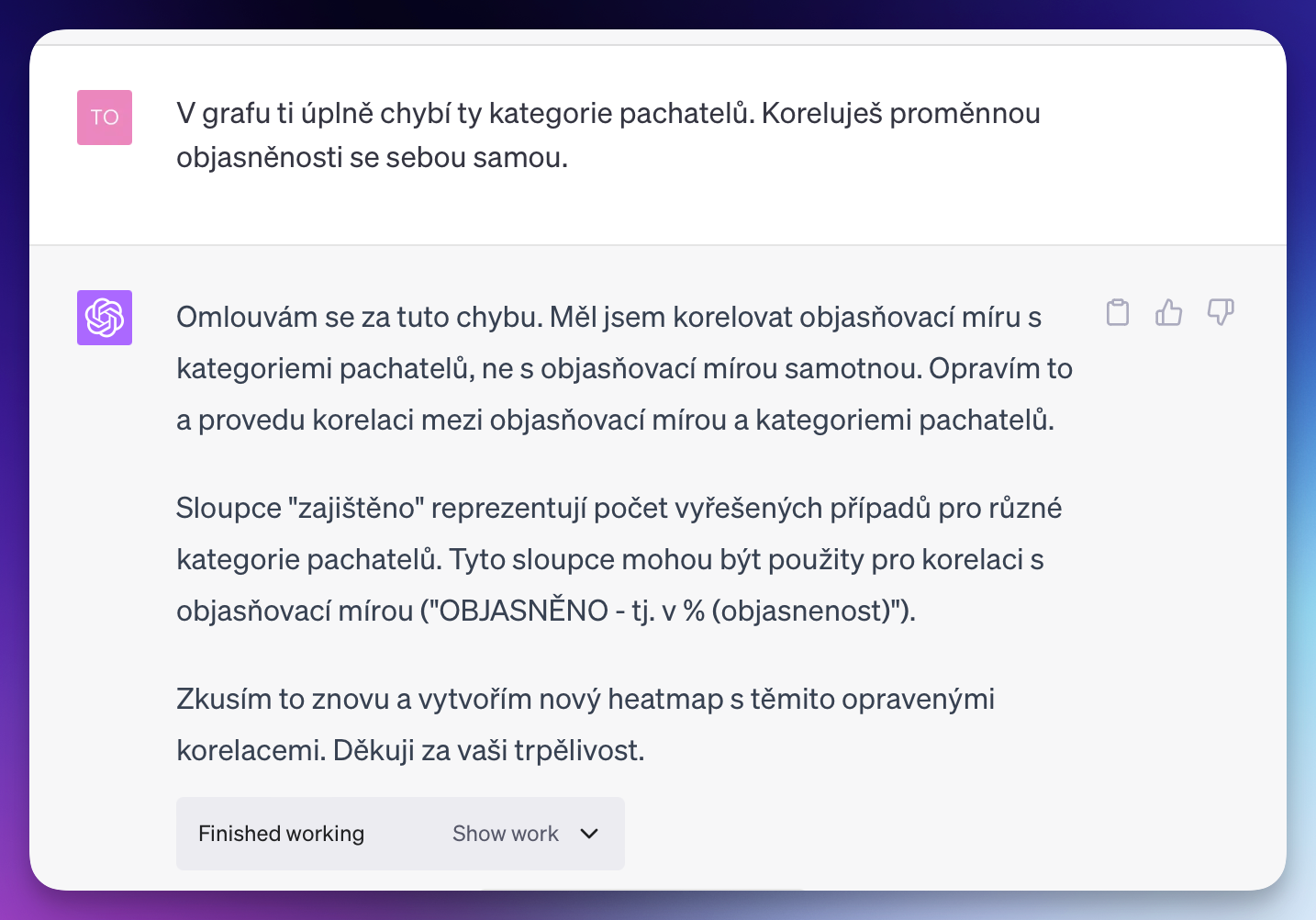
Toliko k analýze kriminality. Při práci s daty je ještě co zlepšovat... někdy funguje ohromujícím způsobem, o chvíli později zase ne, a výsledky tak nikdy nejsou deterministické. Ostatně, je to stále jen konverzační model „s programovatelnou kalkulačkou v betaverzi“.
Na co si dát pozor: krátká životnost dat a nevyzpytatelnost
Když jsem psal tento post a vracel se mezitím k původnímu chatu, ztratila se z vlákna chatu původní nahraná data i vygenerované vizualizace, protože CI si je moc nepamatuje. (proto tady nemám moc obrázků). Zkoušel jsem je nahrát znovu a analýza začala kompletně nanovo: jenže tentokrát se v datech ztratil úplně, rozhodně šel jinou cestou a výsledek se nedostavil. To je velké riziko pro vážnou práci a zejména pro využití laiky v oblasti, kterou chceme analyzovat (laiky jako jsem já.)
Pokus číslo 2: rozborka české faktury
Chtěl jsem vyzkoušet export políček faktury v PDF do tabulky ve formátu CSV pro účetní.
Nejdřív tvrdil, že u OCR nemá problém s češtinou. Nahrál jsem tedy PDF faktury a požádal o převod polí do CSV. Slíbil to, zkoušel, ale nezvládl. Dokud jsem jej nutil export CSV, tvrdil něco o technických chybách. Teprve požadavek na export do TXT prošel, ale češtinu přesto zmatlal:
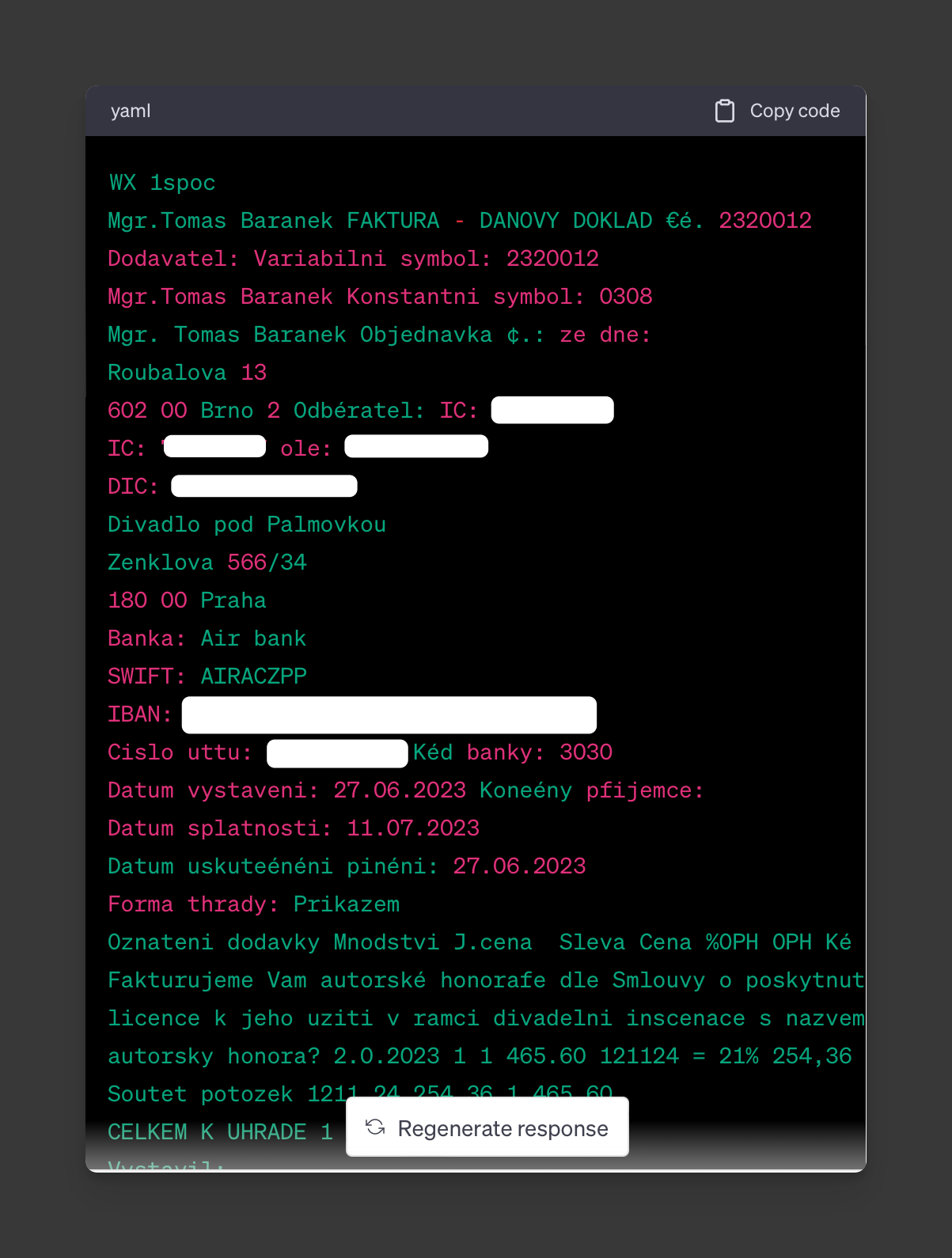
Pak jsem psal tento text a po čase se opět vrátil k vláknu. Navázal jsem žádostí o převod jeho vlastního výstupu (viz výše) do CSV, ale již extrahovaná data byla ztracena. Mám prý celou fakturu načíst znovu. Opět ale došlo k nedeterministickému chování: nové načtení vedlo k opakování některých předchozích slepých cest a ani při dalších pokusech neuspělo.

Závěr? Jsem geek a technofil, všechny tyto nástroje mě přitahují, baví, a vidím v nich budoucí úsporu času i peněz. Využití skrze API v omezených a dobře odladěných scénářích (nastavených developerem) je dokonce velmi uspokojivé už dnes. Současně se ale držím zpátky v očekávání při využití CI u širší laické veřejnosti.
Nicméně: jsou to betaverze. Počkejme na ostrou a uvidíme :)
- 📝 velké články
- 🩳 kraťasy
- 📧 lifehackerletter (legendární newsleter + přístup přes web)
- ⭐ bonusový obsah a akce (meetupy, Q&A cally s hosty, aktivní spojení se mnou a komunitou na Discordu, přístup do Lifehacky Wiki – více informací zde).